Learning 3D Object Shape and Layout without 3D Supervision
|
|
|
|
|
|
|
|
|
|
|
|
|
|
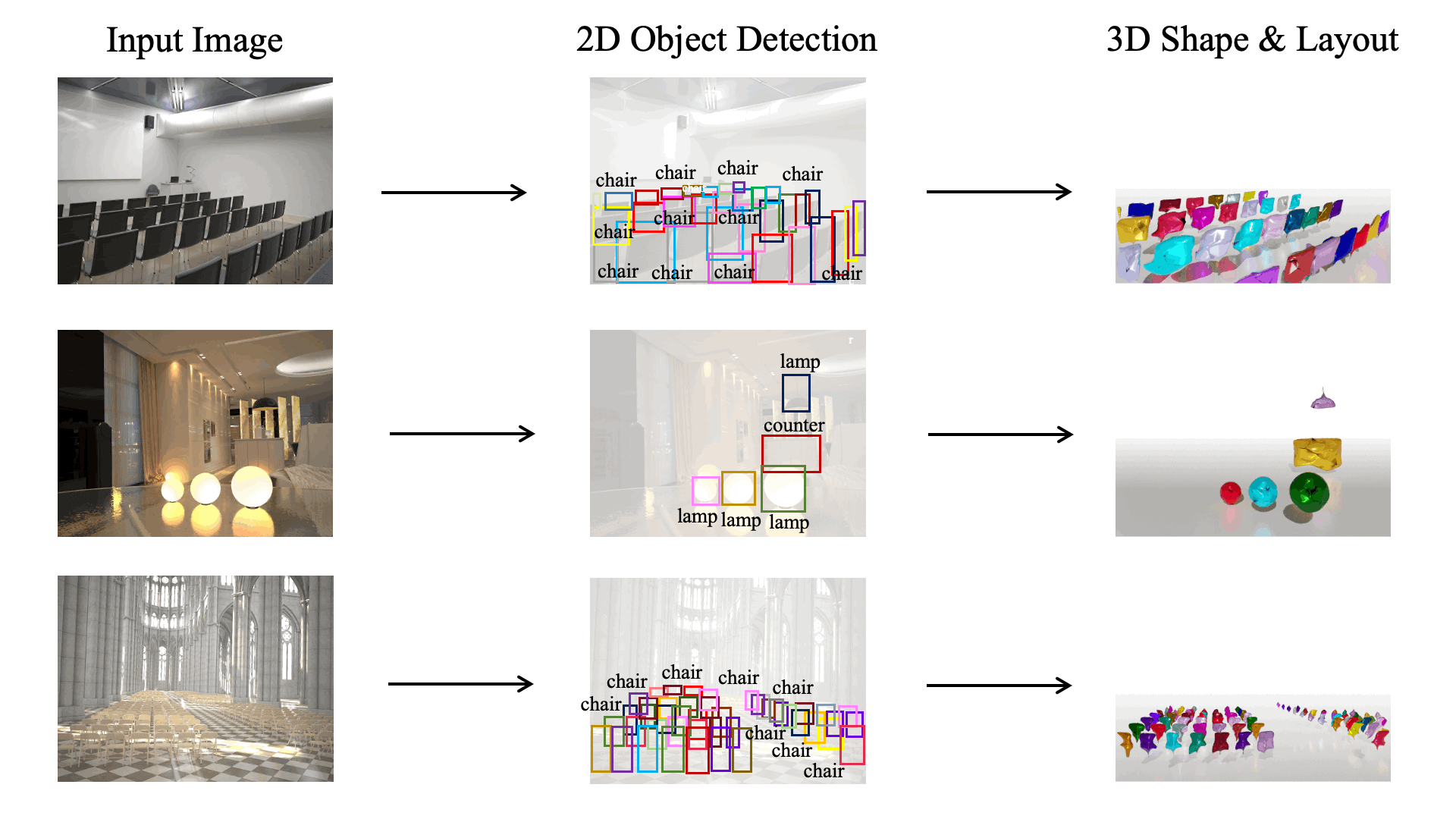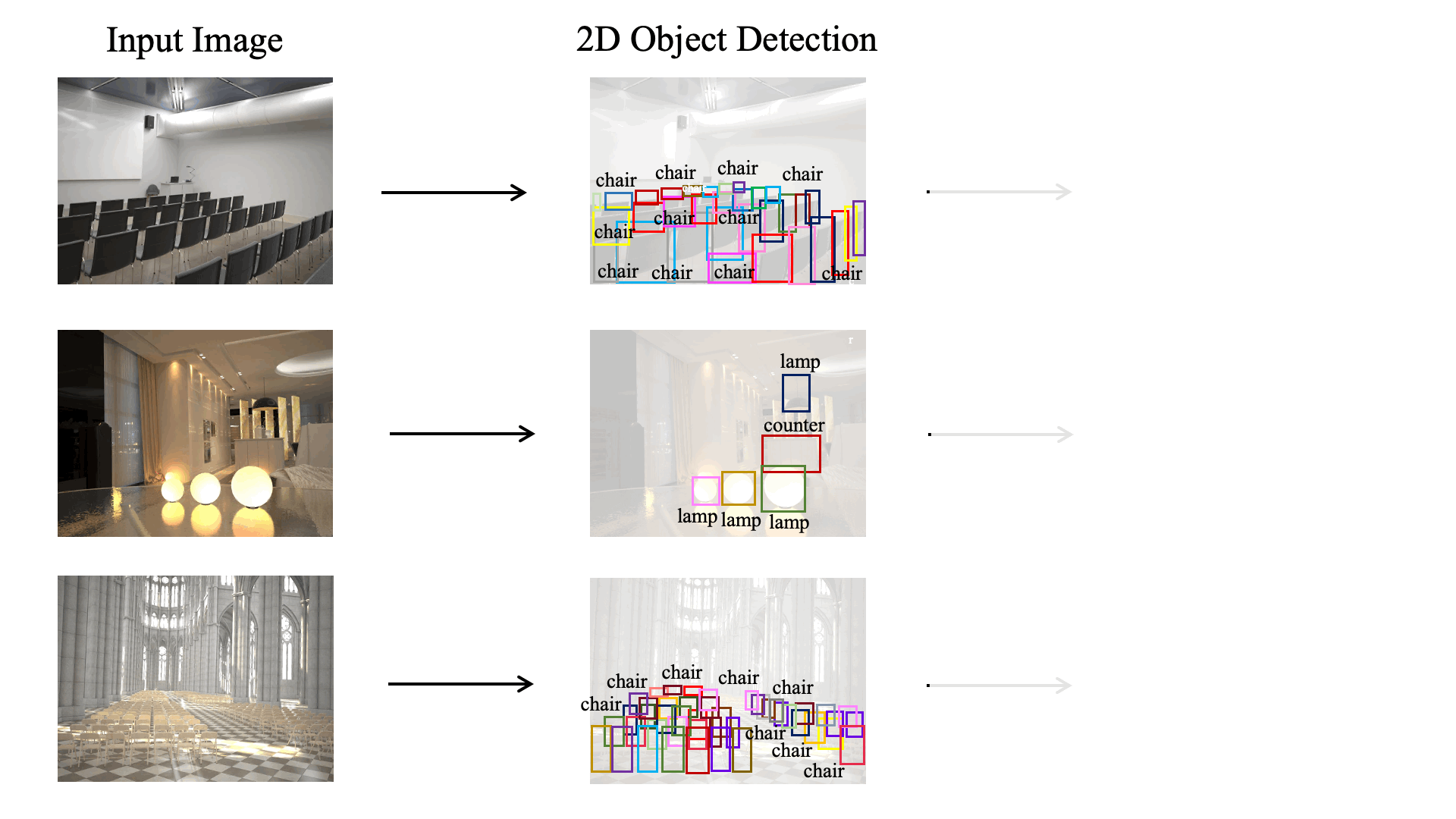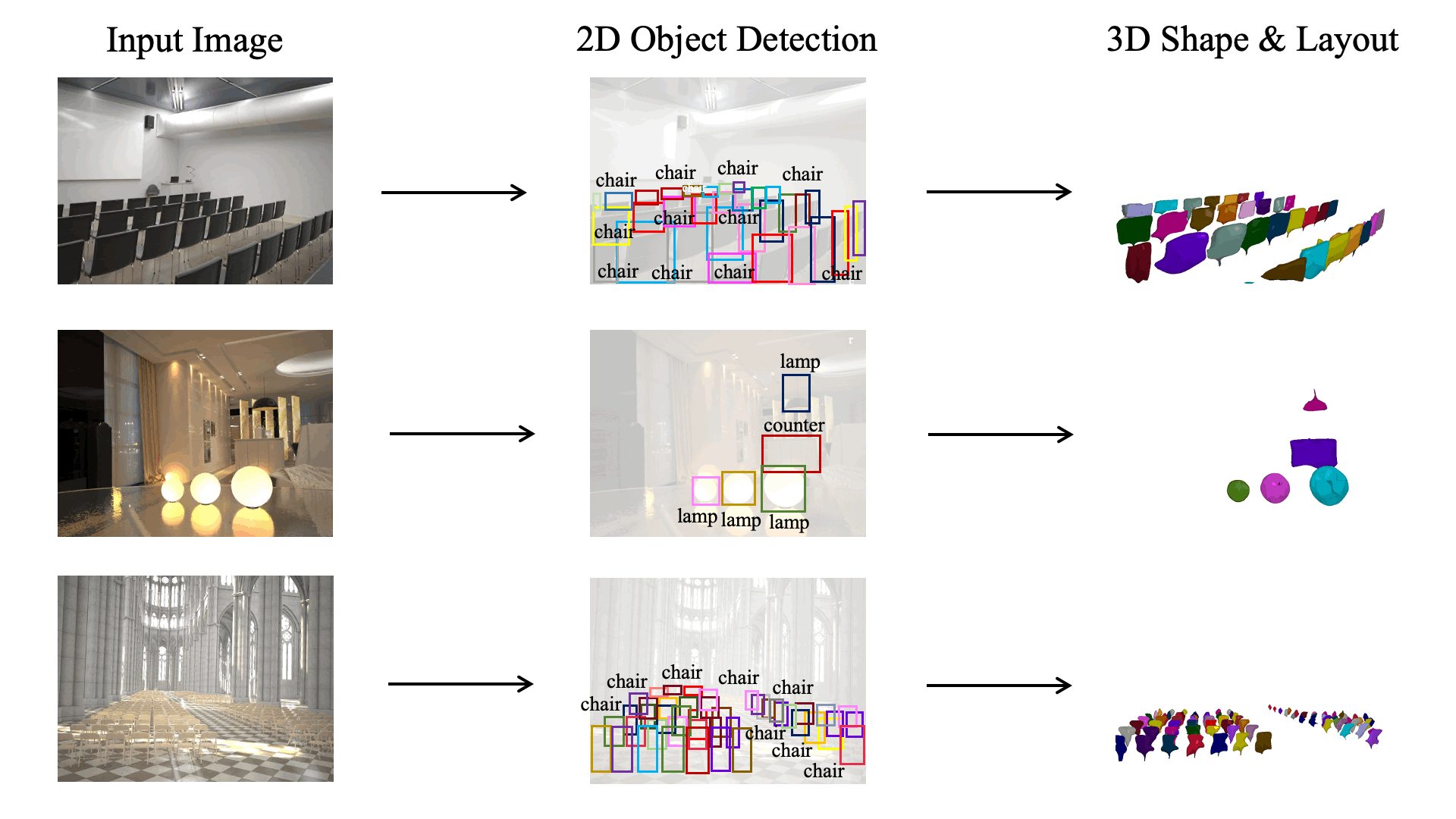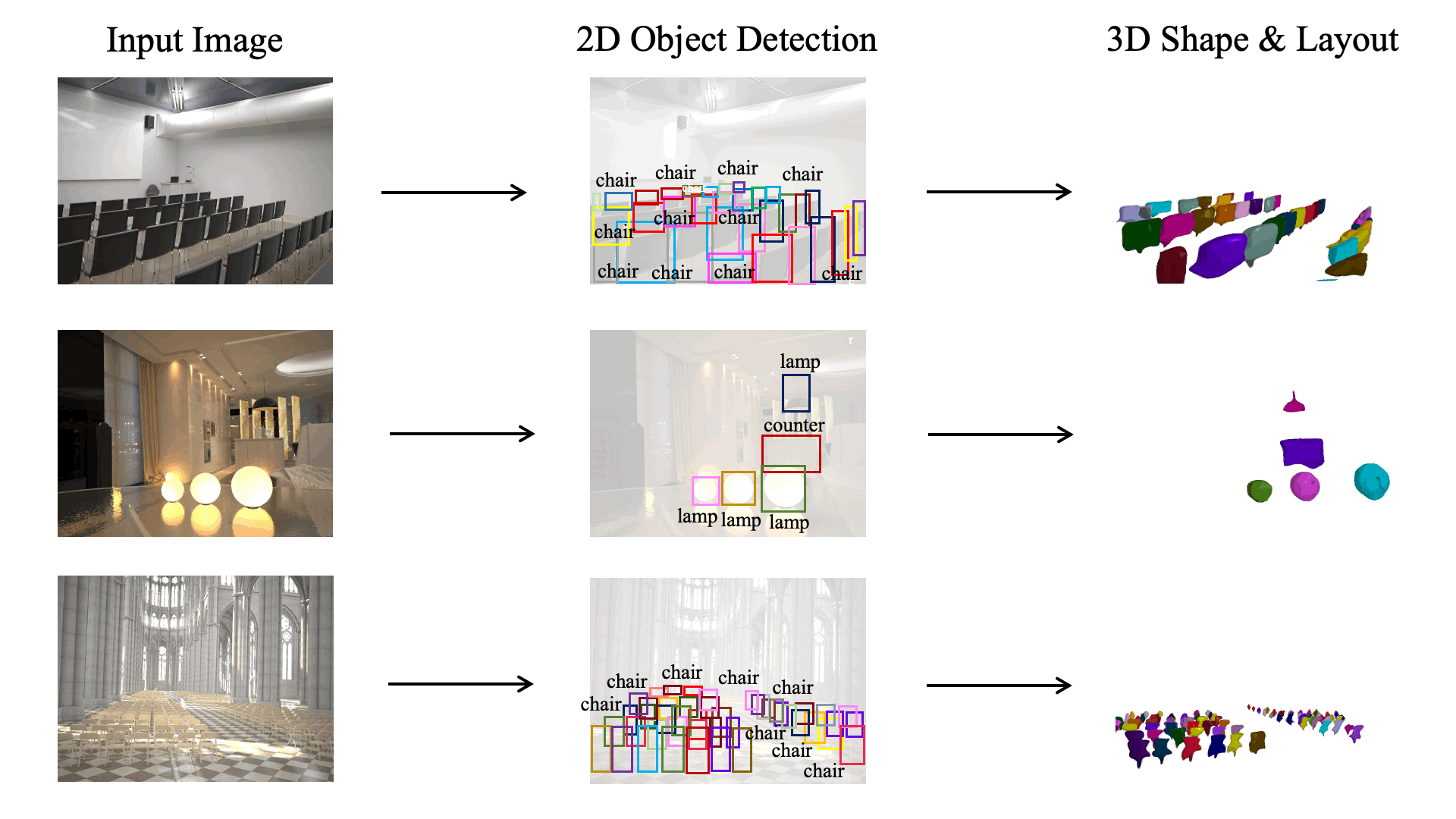
A 3D scene consists of a set of objects, each with a shape and a layout giving their position in space. Understanding 3D scenes from 2D images is an important goal, with applications in robotics and graphics. While there have been recent advances in predicting 3D shape and layout from a single image, most approaches rely on 3D ground truth for training which is expensive to collect at scale. We overcome these limitations and propose a method that learns to predict 3D shape and layout for objects without any ground truth shape or layout information: instead we rely on multi-view images with 2D supervision which can more easily be collected at scale. Through extensive experiments on 3D Warehouse, Hypersim, and ScanNet we demonstrate that our approach scales to large datasets of realistic images, and compares favorably to methods relying on 3D ground truth. On Hypersim and ScanNet where reliable 3D ground truth is not available, our approach outperforms supervised approaches trained on smaller and less diverse datasets.


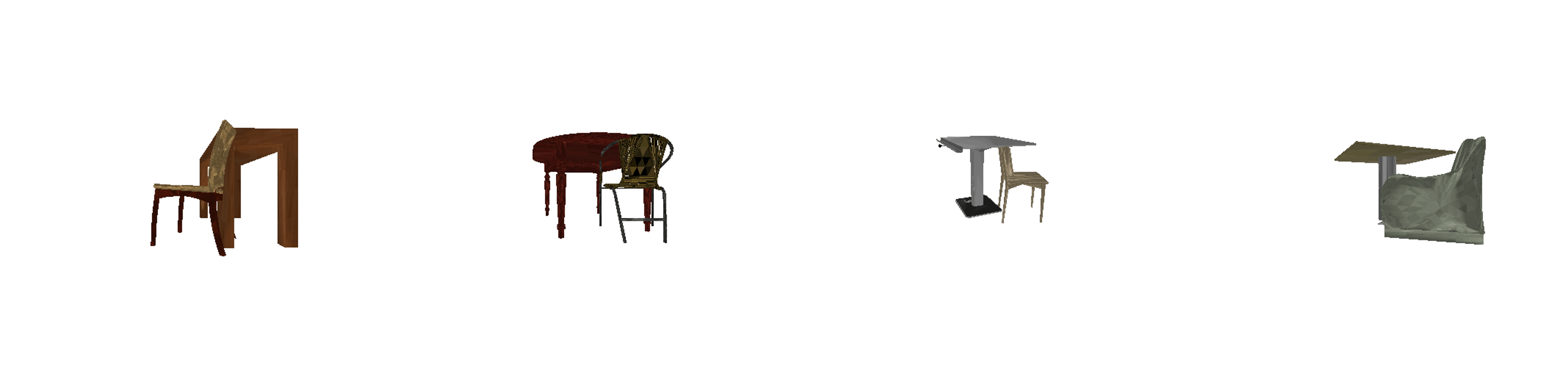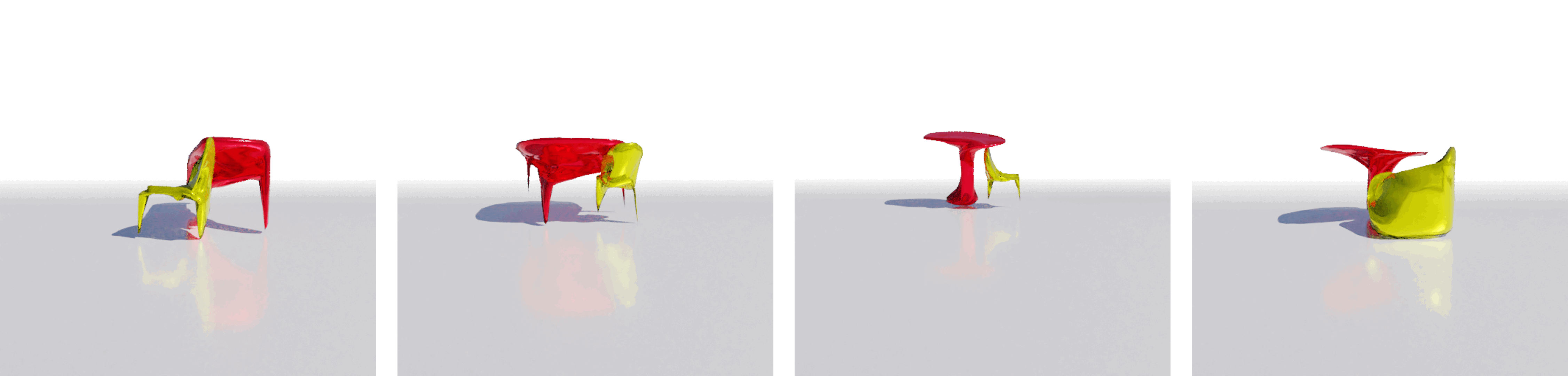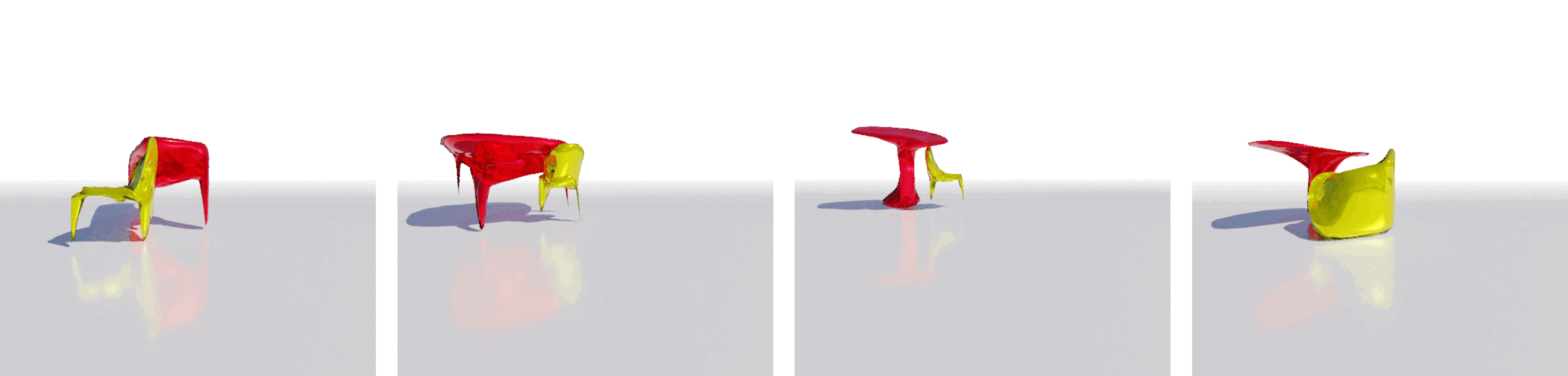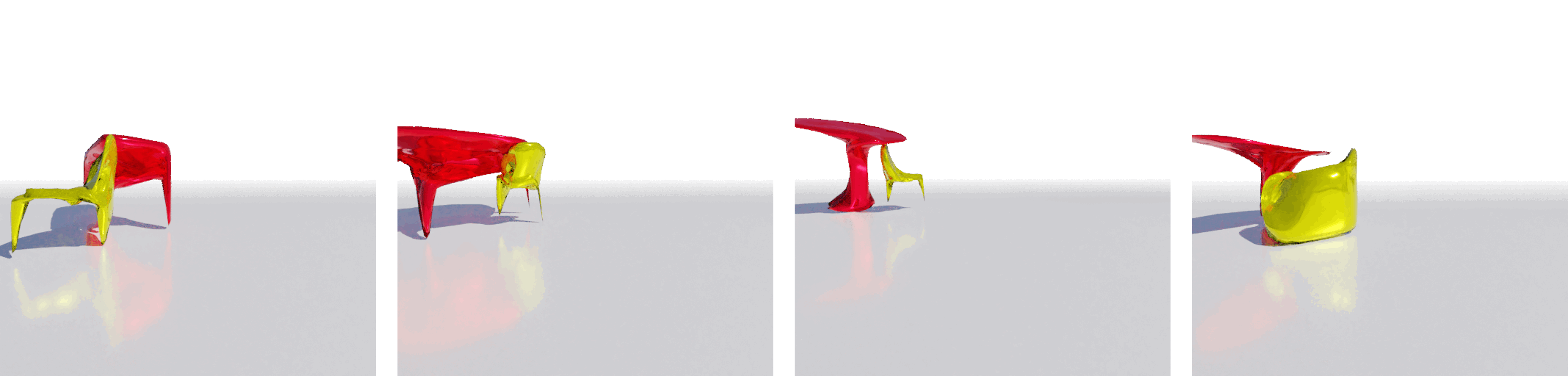
| Input Image | USL | Mesh R-CNN |
|---|---|---|
 |
||
 |
||
 |
||
 |
||
 |
 |
Gkioxari, Ravi, Johnson. Learning 3D Object Shape and Layout without 3D Supervision In CVPR 2022. [bibtex] |
Contact: Georgia Gkioxari